QUBE Servo Pendulum — RL (IsaacLab / PPO / SKRL) + CBF Safety
Development, training, and hardware deployment of RL policies with a CBF safety filter for the Quanser QUBE inverted pendulum.
Overview
This project demonstrates training reinforcement learning policies in NVIDIA IsaacLab (Isaac Sim) using PPO (implemented with SKRL). A Control Barrier Function (CBF) safety filter is used to help enforce state and input safety constraints — applied during training to shape learning and/or during deployment as a shield to block unsafe actions on the real hardware.
QUBE: Angles & Notation

Training & Workflow
- Trained policies in IsaacLab without domain randomization and recorded training logs and videos.
- Trained and compared runs with and without CBF-RL implementations.
- Evaluated trained policies in IsaacLab and recorded evaluation logs and videos.
- Exported trained policies (as ONNX) for real hardware deployment.
- Deployed trained policies to the real QUBE hardware using zero-shot transfer, with a safety filter enabled during deployment.
Videos
IsaacLab training
Sim-in-the-loop / evaluation
Real hardware deployment
Results
To compare the effect of a Control Barrier Function (CBF) on learning and deployment we evaluate four cases:
- CBF in learning and shielding — the barrier is used to shape learning and also applied during deployment (shielding) to prevent unsafe actions.
- CBF in learning only — the barrier is used during training to guide the agent, but is not active during deployment.
- CBF in shielding only — the agent is trained without a CBF, but a shielding filter is applied during deployment to restrict unsafe commands.
- No CBF in learning and shielding — baseline: the agent is trained and deployed without any barrier safety filter.
Case (steady): In the 'CBF in learning and shielding' case the agent steadily converged to a stabilizing policy, and the shielding prevented large unsafe commands during deployment.
Reward vs Episode number:
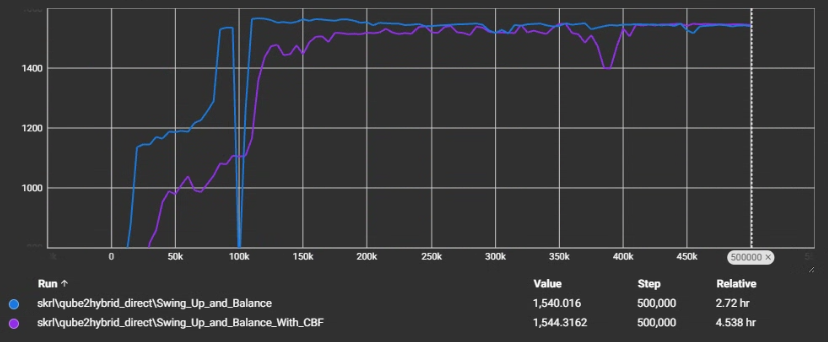
About the reward graph: The reward plot shows episode-averaged returns during training (x-axis = training steps / episodes; y-axis = average reward). Higher rewards correspond to better swing-up and balancing performance. Steep rises indicate faster learning, plateaus indicate convergence, and sharp dips indicate failed or unstable episodes. In our experiments, policies trained and deployed with a CBF (both learning and shielding) tended to converge more quickly and produce consistently higher rewards than baseline runs without CBF.
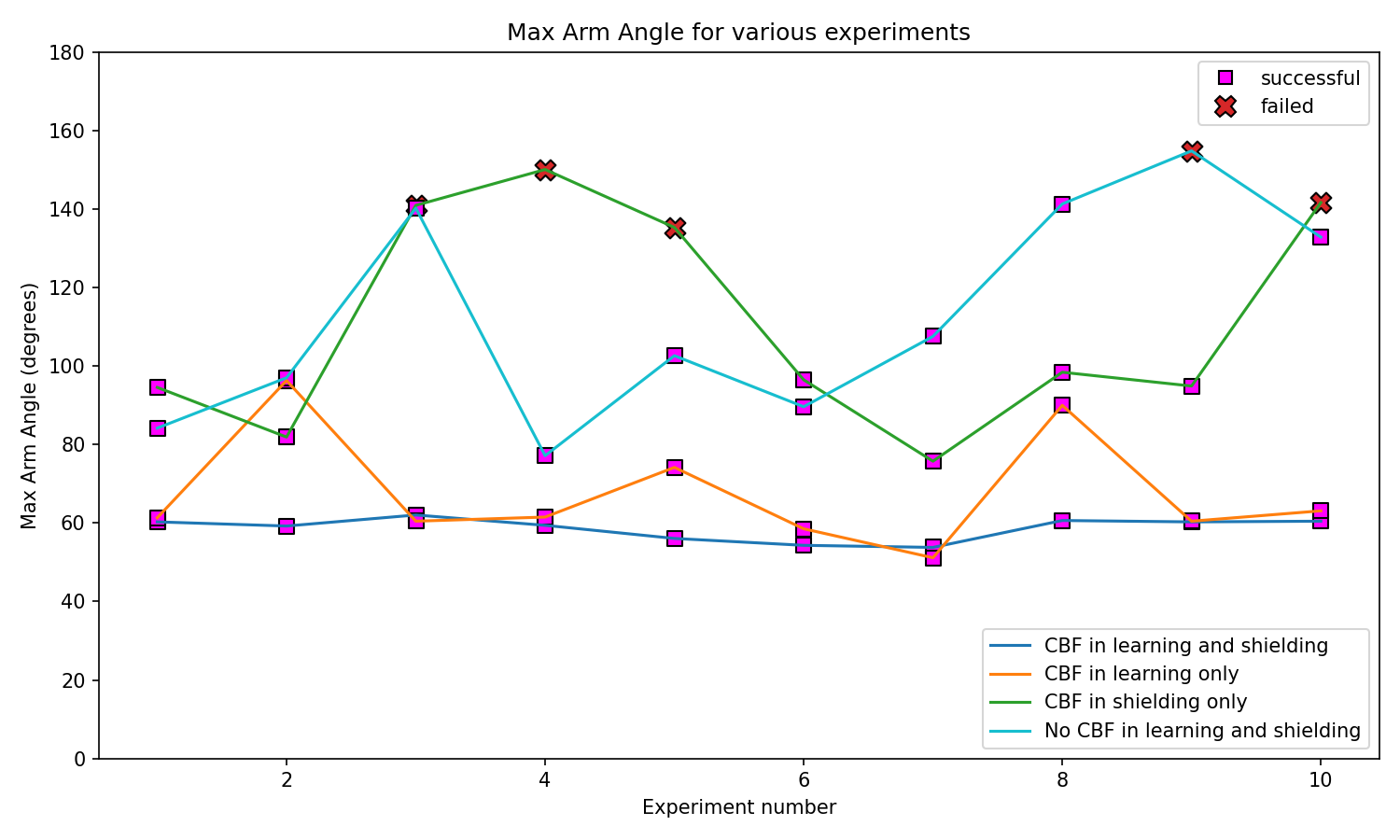
About the max arm angle graph: This plot shows the peak arm rotation observed during each evaluation. Lower peak angles indicate better overall control and fewer large excursions. In our experiments, CBF-enabled runs typically exhibit reduced peak arm angles, fewer sudden spikes, and lower failure rates than baseline runs without CBF.
Max Arm Angle (horizontal rotation) vs evaluation run.
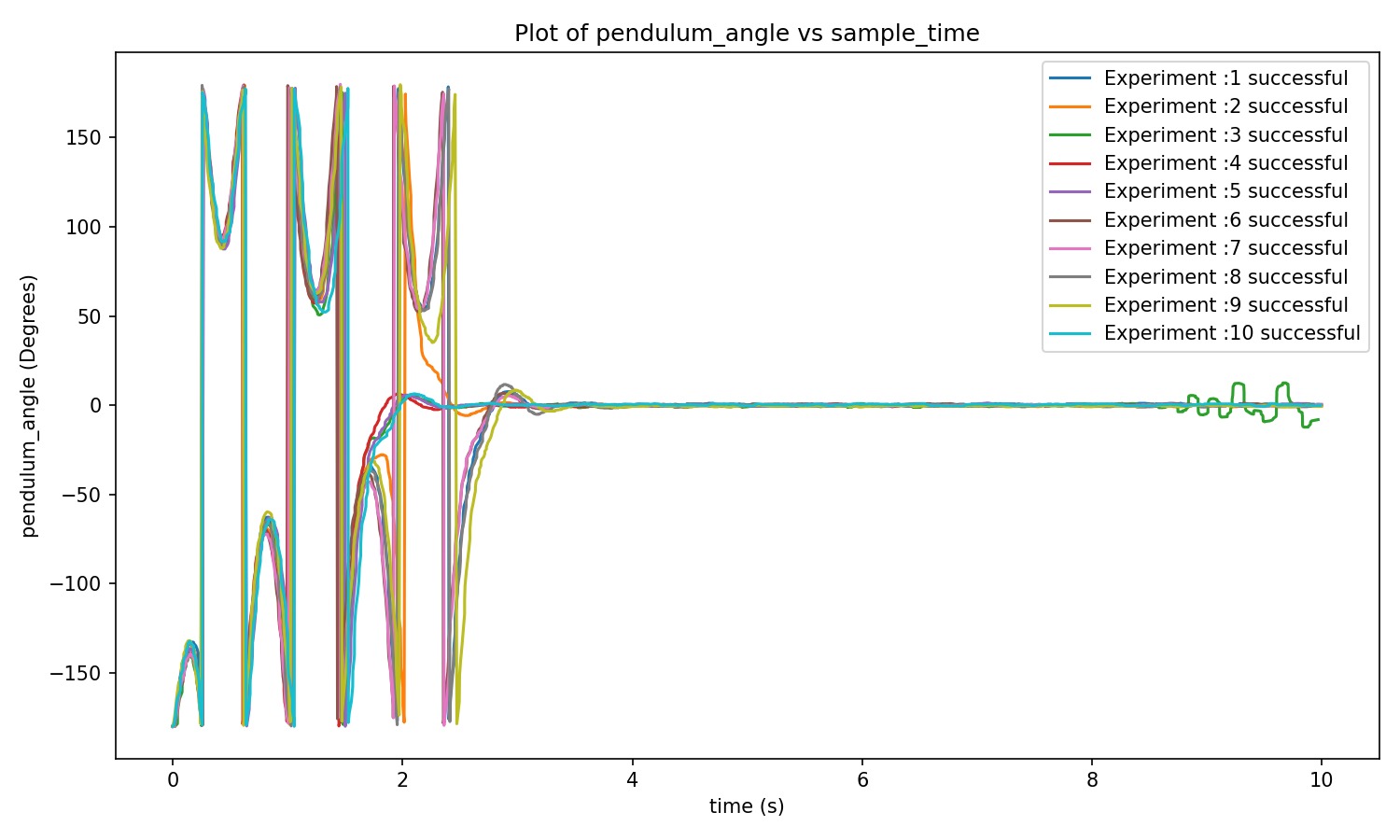
Note: A pendulum angle response plot (ϕ vs. time/episode) will be added here to illustrate the pendulum's response and stabilization performance.
Pendulum response (CBF in learning & shielding): For the 'CBF in learning and shielding' case, the pendulum angle stabilizes quickly to the upright configuration with limited overshoot and reduced oscillations. This behavior indicates effective stabilization when the policy has been trained with a CBF and a shielding filter is applied during deployment.